Readpaper | OccWorld: Learning a 3D Occupancy World Model for Autonomous Driving

Background
3D占用预测
3D占用预测旨在预测3D空间中的每个体素是否被占用以及其语义标签是否被占用。
现有的方法只关注于获得三维语义占用,而忽略了其时间演变,这对自动驾驶的安全至关重要。
自动驾驶的世界模型
通常被定义为在给定动作和过去的情况下产生下一个场景观察
SD在2D图像空间中产生的未来观测结果,缺乏3D场景理解,或者其他使用未标记的激光雷达数据,忽略了语义信息
端到端自动驾驶
最近的方法是在给定传感器输入的情况下输出路径的规划结果
Occworld提出了一个世界模型来预测周围动态和静态元素的演变
Motivation
对于自动驾驶,大多数现有方法遵循传统的感知、预测和规划流程。
感知旨在获得对周围场景的语义理解,如3D检测和语义图构建
预测指捕获其他交通参与者的运动
规划模块根据先前的输出做出决策
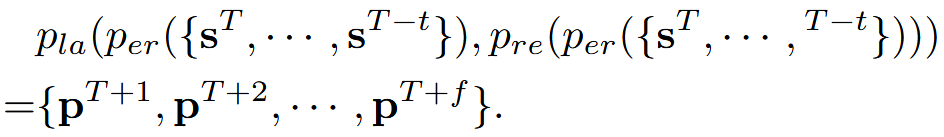
缺点
每个阶段都需要GT
实例级box和高清晰度地图很难标注
通常只预测目标边界框的运动,无法捕捉到有关3D场景的更细粒度的信息
Occworld是一种新的范式,可以同时预测周围场景的演变,并规划自动驾驶汽车的未来轨迹。
Method

World Model for Autonomous Driving
自动驾驶的目标是在给定过去t个传感器输入s、3D ego position(p) ,预测从当前T时刻起,未来f个时刻的p
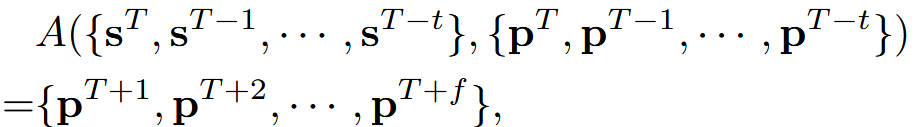
传统pipeline通常遵循感知、预测和规划的设计。
感知模块per感知周围的场景,从输入的传感器数据 s 中提取高级信息 z
预测模块 pre 综合高层信息 z 预测场景中每个代理的未来轨迹 ti
规划模块 pla 最后处理感知和预测结果 {z,{ti }},规划车辆的运动
定义了一个世界模型w来作用于场景表示y,并能够预测未来的场景
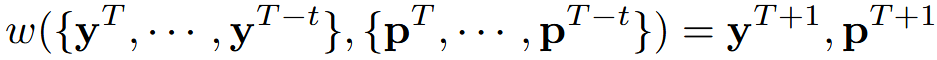
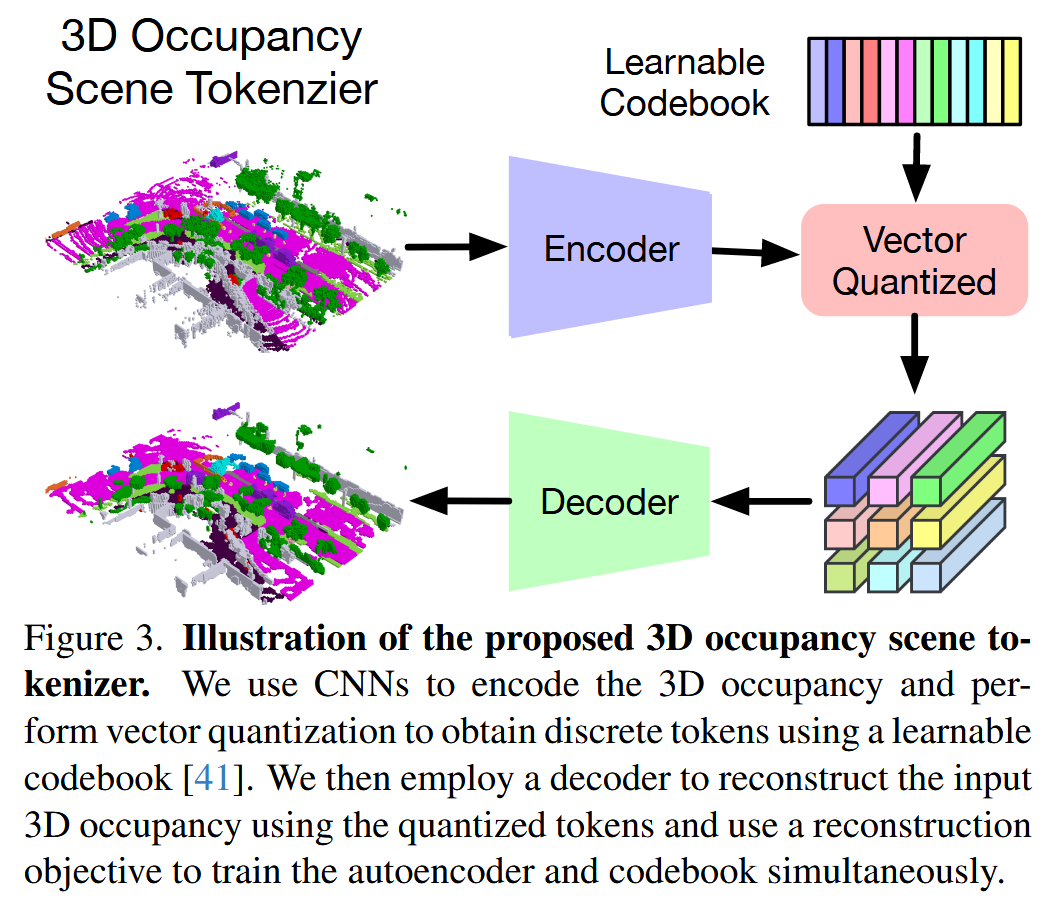
3D Occupancy Scene Tokenizer
根据三个原则选择场景表示y:
expressiveness,它应该能够全面地包含3D场景的3D结构和语义信息
efficiency
多功能性(versatility),它应该能够适应视觉和激光雷达模式
用3D Occupancy作为3D场景表示y∈R^(H×W×D),并为每个体素分配一个标签l
尽管3D占有率很全面,但它只提供了对场景的低级理解,很难直接模拟其演变
Occworld提出了一种自监督的方法,将场景标记为来自3D占用的高级标记。在y上训练矢量量化自动编码器(VQ-VAE),以获得离散标记z,从而更好地表示场景
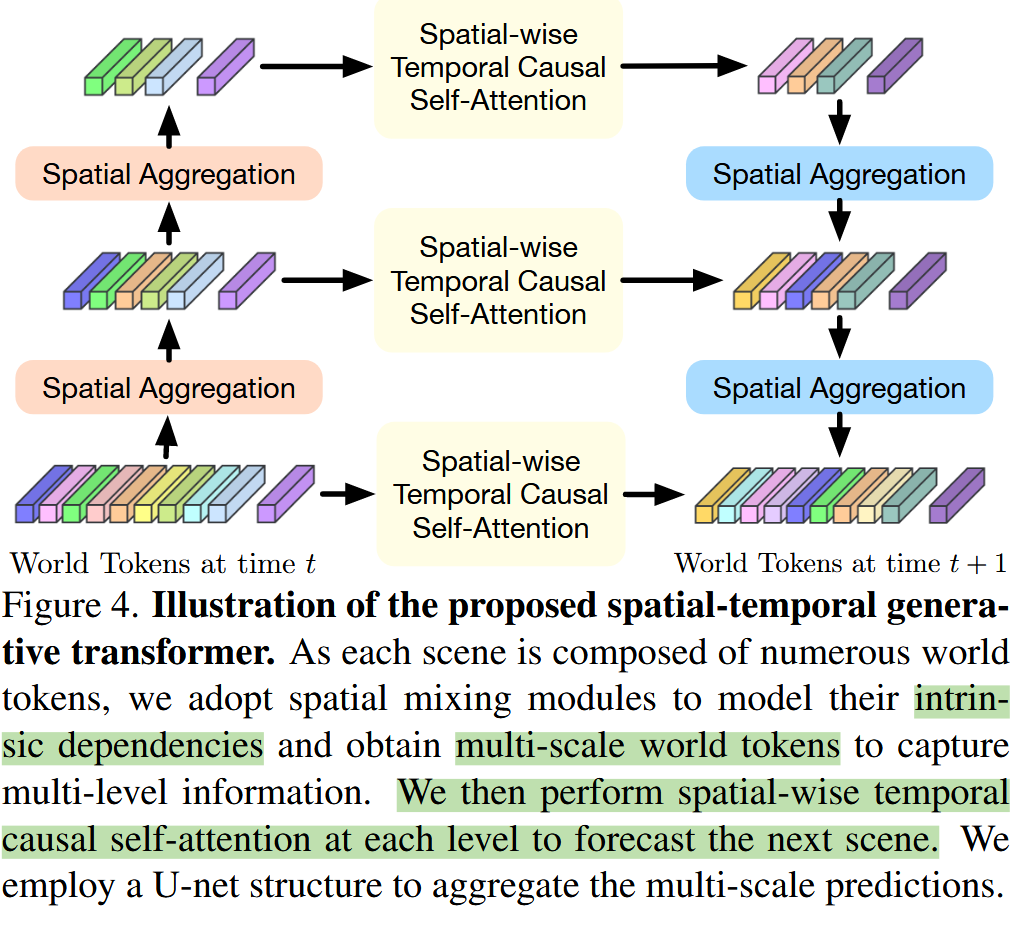
Spatial-Temporal Generative Transformer
世界模型w将过去的场景和ego位置作为输入,并在一定时间间隔后预测它们的结果
使用一个自监督的tokenizer来获得高级别的场景标记 T={z_i }
将 T 与自我标记 z_0∈R^C聚合,以编码自我车辆的空间位置
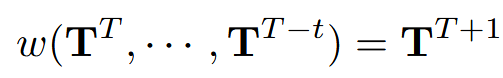
OccWorld: a 3D Occupancy World Model
采用两阶段的训练策略来训练OccWorld。对于第一阶段,使用3D占用损失训练场景tokenizer e和解码器d:
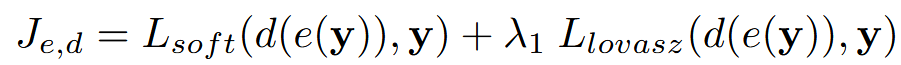
对于第二阶段,采用学习的场景tokenizer e来获得所有帧的场景标记z,并约束预测tokes z^和z之间的差异。
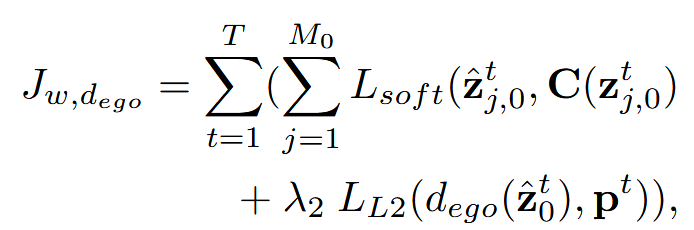
为了有效训练,使用场景标记器e获得的标记作为输入,但应用masked 的时间注意力来阻止未来tokens的效果。在推理过程中,逐步预测下一个帧。
Experiments
在Occ3D数据集上进行4D占用预测
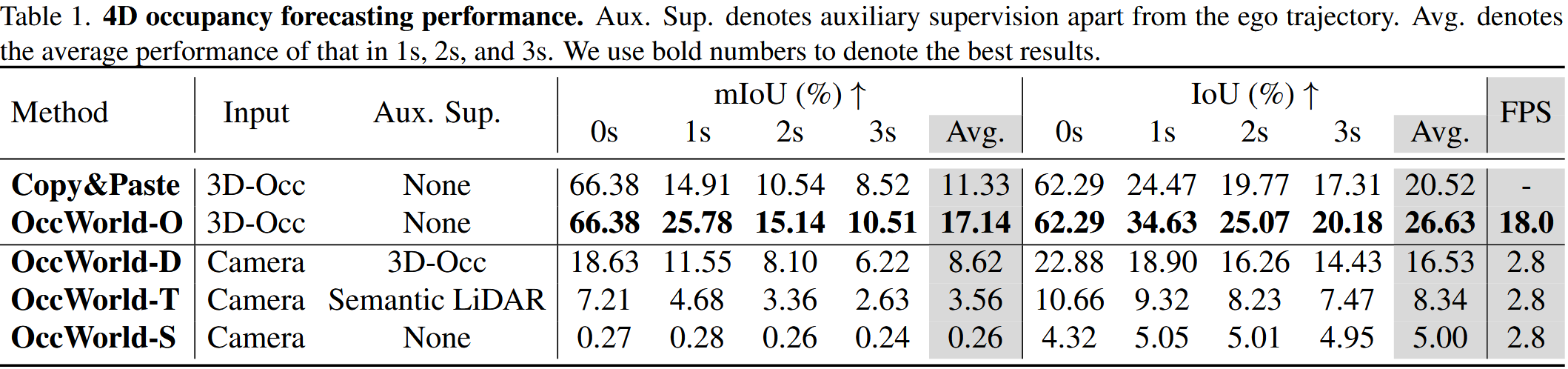
OccWorld-O: 使用真实的3D占用数据(ground-truth 3D occupancy)作为输入。 模型直接使用精确的3D占用信息来预测未来的占用状态 ,代表了模型在理想情况下的性能,即输入数据是完全准确的。
OccWorld-D: 使用TPVFormer模型预测的结果,模拟了在有高质量标注数据的情况下,通过另一个模型(TPVFormer)预测3D占用,然后将这些预测用作OccWorld模型的输入。
OccWorld-T: 使用TPVFormer模型预测的结果,考虑了在数据标注较少或数据稀疏的情况下,模型的性能如何。
OccWorld-S: 使用TPVFormer模型预测的结果,该模型以自监督方式训练,探索了在没有人工标注数据的情况下,仅依靠自监督学习得到的3D占用预测作为输入时,OccWorld模型的性能。
Copy&Paste: 将当前的真实3D占用数据直接复制作为对未来的预测,baseline
在nuScenes数据集上执行运动规划
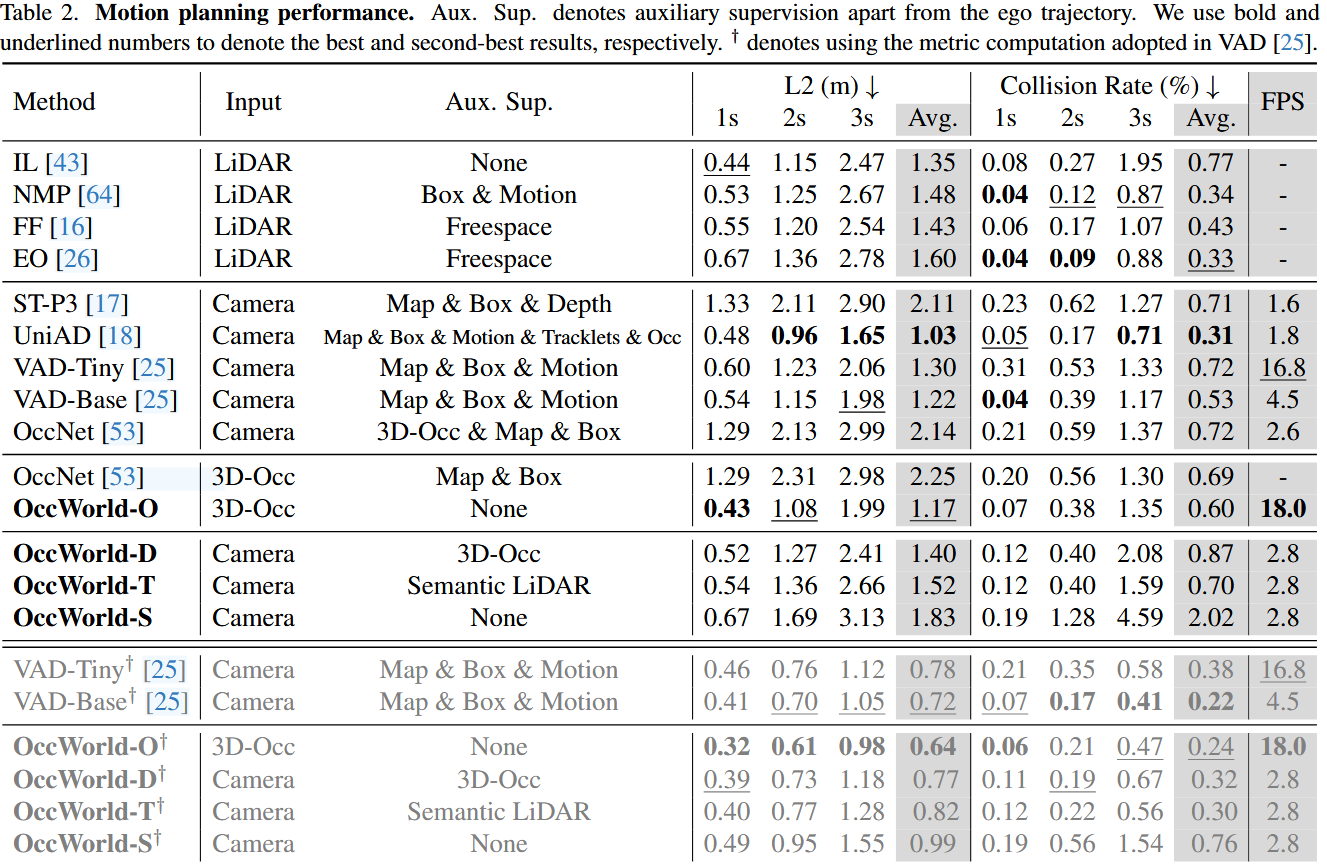
OccWorld-O 在不使用地图和边界框作为监督的情况下,以很大的优势超过了之前基于感知预测规划的方法 OccNet
OccWorld-D和OccWorld-T在仅使用三维占位作为监督的情况下也表现出了极具竞争力的性能,而OccWorld-S在除未来轨迹外无任何监督的情况下也取得了不俗的成绩,显示了可解释的端到端自动驾驶的潜力。
在 L2 误差方面表现出很强的竞争力,但在碰撞率方面却稍显落后
Ablation
Analysis of the scene tokenizer

setting(潜在空间分辨率、潜在通道维度和codebook大小)
使用大于 512 的codebook会导致过度拟合,而使用较小的编码本、空间分辨率或信道维度可能不足以捕捉场景分布。空间分辨率越大,重建精度越高,但预测和规划性能却越差。这是因为标记无法学习高级概念,难以预测未来。
Analysis of the spatial-temporal generative transformer.
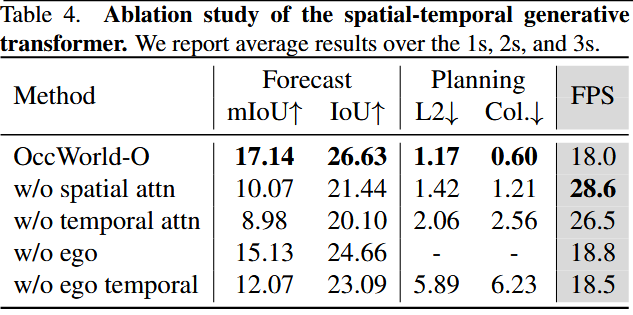
w/o temporal attn 表示用简单的卷积来代替时间注意力
w/o ego 表示放弃了 ego 标记