Readpaper | TPVFormer: An academic alternative to Tesla's Occupancy Network

TPVFormer: An academic alternative to Tesla's Occupancy Network

Related Projects
Our code is based on BEVFormer and Cylinder3D. Many thanks to them!
Welcome to see SurroundOcc for a more dense 3D occupancy prediction. You can also use SurroundOcc's generated dense occupancy ground truths for training instead of sparse lidar supervision.
Also, remember to check out OccFormer for an effective and efficient transformer encoder-decoder specially designed for occupancy prediction.
Background
传统的方法是使用BEV,这种方法的细节不够,并且很难使用扁平化矢量对所有这些矢量进行编码
要解决的问题是如何从BEV来建模细粒度的3D结构并且保持高效和检测的性能
Motivation
motivated by 显式-隐式混合场景表示法,本文对 BEV 进行了泛化,用两个相互垂直的平面来构建三个相互垂直的交叉平面。
Method
概述方法
要获得一个点在3D空间的feature,先将这个点投影到三个平面,使用bilinear interpolation来获得特征,然后sum三个投影特征,然后就可以用TPV表示来描述这个场景。TPV representation是3D域的东西。
TPVFormer
用于从2D图像中高效的获得TPV特征
在TPV grid queries 和2D image之间使用cross attn来将2D信息提升到3D空间
然后在三个平面之间使用 cross-view hybrid-attention来enable interaction
Generalizing BEV to TPV
一个三维点(x,y,z)投影到二维(h,w)空间中,对于某个二维空间中的点(h,w),它的特征b_{h,w}包含了点(x,y,z)点的所有z轴上的feature
f_{x,y,Z}=b_{h,w}=S(B,(h,w))=S(B,P_{bev}(x,y))
其中f_{(x,y,Z)}指的是同一个(x,y)但是不同z的所有点,P_{bev}是 point to BEV projection
完全省略 Z 轴会对其表现力产生不利影响,因此本文提出了TPV,三视角表示,能够表示出3D空间但是又没有体素那么大的计算量。
Point Querying formulation
给定现实世界中位于(x,y,z)处的一个查询点,TPV 表示法试图将其在顶视图、侧视图和正视图上的投影汇总起/来,以获得对该点的全面描述。
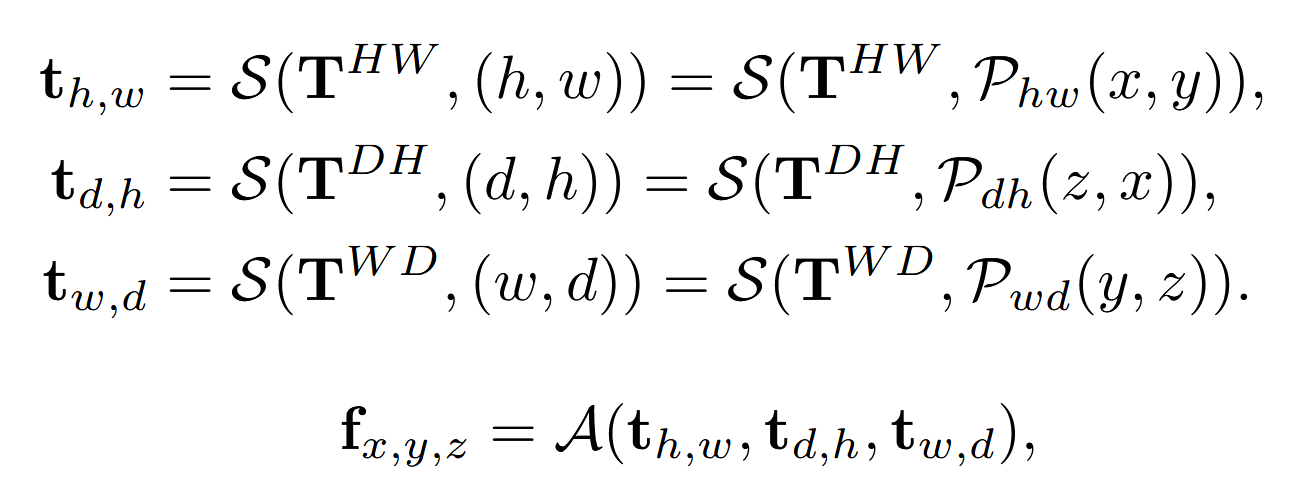
Voxel feature formulation使用TPV平面之后能够获得和voxel类似的特征空间,但是计算复杂度最多是O(HW+DH+WD).
TPV 表示法将 BEV 从单一的俯视图扩展到互补和正交的俯视图、侧视图和正视图,能够更全面、更精细地了解周围的三维环境,同时保持高效。
TPVFormer
通过注意机制将图像特征提升到TPV平面。
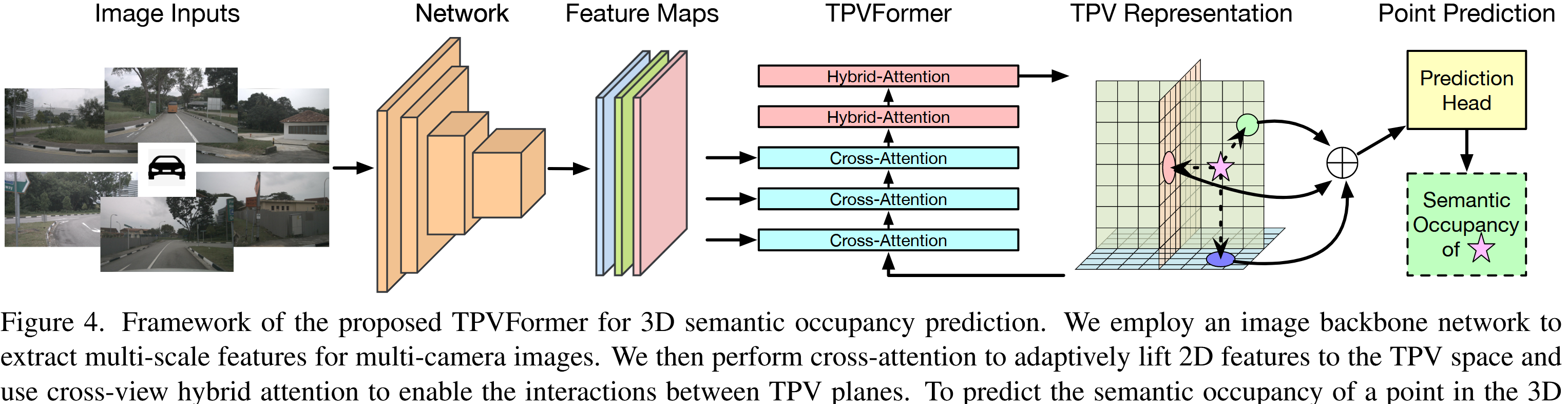
涉及到三个部分:TPV queries, image cross-attention (ICA) 和 cross-view hybrid attention (CVHA)
TPV queries
如前文所定义的一致,它们被用于注意力和三维表示情境中
在本文的流程中,TPV查询首先利用 HCAB 块中图像特征的原始视觉信息进行增强,然后利用 HAB 块中其他查询的上下文线索进行完善。实现上,将TPV查询初始化为可学习参数,并在第一个编码器层之前为其添加三维位置嵌入。
Image Cross-Attention
用于将多尺度和可能的多相机图像特征提升至TPV平面
这里有一个尺度的问题,TPV查询的量级是10^4但是多个图像的feature map数量级是10^5,因此这里使用了deformable attention
通过采样参考点来提升图像特征到TPV平面。这个过程涉及到以下几个步骤:
- 局部感受野作为归纳偏置:在采样参考点时,作者使用了局部感受野(local receptive field)作为归纳偏置。这意味着在采样时,系统会考虑查询点在特征空间中的局部邻域,而不是在整个空间中随机或均匀采样。
- 计算真实世界中的坐标:对于位于顶部平面的TPV查询点 t_{h,w} (其在TPV平面上的坐标为 ( (h, w) )),首先通过逆投影函数 ( P^{-1}_{hw} )计算其在真实世界顶视图中的坐标 ( (x, y) ) 。逆投影函数的作用是将TPV平面上的点映射回真实世界的坐标系中。
- 均匀采样参考点:在确定了查询点 ( t_{h,w} ) 在真实世界中的坐标后,接下来沿着平面的正交方向均匀采样 ( N_{HW}^{ref} ) 个参考点。这里的 ( N_{HW}^{ref} ) 表示采样的参考点数量,( HW ) 可能表示与TPV平面的分辨率有关。正交方向意味着与当前的TPV平面垂直的方向,例如,如果当前平面是水平的,那么正交方向就是垂直方向。
描述了图像交叉注意力(Image Cross-Attention,简称ICA)的计算过程
- ICA函数:ICA(t_{h,w}, I) 表示图像交叉注意力函数,它将一个TPV查询点 t_{h,w} 和一组图像特征 I 作为输入。
- 归一化因子:\frac{1}{|N_{val}^{h,w}|} 是一个归一化因子,其中 |N_{val}^{h,w}| 表示有效相机的数量。这个因子确保了不同数量的有效相机对结果的影响是均衡的。
- 求和:\sum_{j \in N_{val}^{h,w}} 表示对所有有效相机 j 进行求和。有效相机是指那些能够捕捉到查询点 t_{h,w} 的参考点的相机。
- DA函数:DA(t_{h,w}, Ref_{pix,j}^{h,w}, I_j) 表示可变形注意力(Deformable Attention)函数。这个函数计算TPV查询点 t_{h,w} 与第 j 个相机的图像特征 I_j 之间的注意力权重,并根据这些权重采样图像特征。
- 参考点集:Ref_{pix,j}^{h,w} 表示第 j 个相机中查询点 t_{h,w} 的参考点集。这些参考点是在图像空间中的位置,用于从图像特征中采样信息。
对于一个给定的TPV查询点 t_{h,w},我们从所有能够捕捉到该点的相机中均匀采样参考点,然后使用可变形注意力机制计算每个参考点的注意力权重,并将这些加权的图像特征求和。最后,我们通过有效相机的数量来归一化这个求和结果,得到最终的图像交叉注意力输出。
Cross-View Hybrid-Attention
用于TPV queries在不同视图之间交换信息,促进上下文信息的提取。
deformable attention to reduce computation
-
分组参考点:对于位于顶部平面的TPV查询点 t_{h,w},将其参考点分为三组,分别对应顶部、侧面和前面三个正交平面:
R_{h,w} = R_{top_{h,w}} \cup R_{side_{h,w}} \cup R_{front_{h,w}} -
采样参考点:在顶部平面上,直接在查询点 t_{h,w} 的邻域内采样一些随机点作为参考点。对于侧面和前面平面,首先沿垂直于顶部平面的方向均匀采样3D点,然后将这些点投影到侧面和前面平面上:
R_{side_{h,w}} = \{(d_i, h)\}_i R_{front_{h,w}} = \{(w, d_i)\}_i -
计算注意力权重和采样特征:对于每个参考点,通过线性层计算采样偏移和注意力权重,然后将采样到的特征加权求和:
CVHA(t_{h,w}) = DA(t_{h,w}, R_{h,w}, T)
其中,DA(\cdot) 表示可变形注意力函数,它根据参考点和对应的注意力权重来采样特征。
CVHA中,模型不仅考虑了单个视图内的局部信息,还通过注意力机制整合了其他两个正交视图的信息
Experiments
3D semantic occupancy prediction
训练数据是有语义标签的稀疏激光雷达点,任务是vision-based 3d semantic occupancy prediction
没有benchmark,所以只做了定性分析
LiDAR segmentation
要预测给定点的语义标签,本实验用RGB图像作为输入,点仅用于查询其特征和训练阶段的监督
semantic scene completion (SSC)
给定一个lidar扫描,需要确定是不是occupied以及它的语义标签。
RGB图像作为输入,而不是传统的lidar数据,在训练过程中,使用体素标签来监督模型的学习。
Datasets
The Panoptic nuScenes dataset:collects 1000 driving scenes of 20 seconds duration each, and the keyframes are annotated at 2Hz. Each sample contains RGB images from 6 cameras with 360◦ horizontal FOV and point cloud data from 32 beams LiDAR sensor.
The SemanticKITTI dataset:is a large-scale outdoor-scene dataset, which includes automotive LiDAR scans voxelized into 256 × 256 × 32 grids. Each voxel has a side length of 0.2m and is labeled with one of 21 classes (19 semantic, 1 free and 1 unknown).